En esta nota trataremos de conceptualizarlos y propondremos un set de herramientas para una primer mirada exploratoria.
Supuestos subyacentes
Existen cuatro supuestos muy típicos en los análisis estadísticos, es decir, que los los datos "se comportan como...". Y son los siguientes:- Aleatoriedad, o ruido blanco para series de tiempo
- Proveniencia de una distribución dada
- La distribución tiene una medida de posición fija dada
- La distribución tiene una medida de dispersión fija dada
respuesta = componente determinístico + componente aleatorio
a lo siguiente
respuesta = constante + error
la constante sería nuestra medida de posición fija a determinar. Así pues, podemos imaginar el proceso a la mano de estar operando bajo condiciones constantes que producen una sola columna de datos con las propiedades que:
- los datos no están correlacionados entre sí;
- la componente aleatoria tiene una distribución fija;
- el componente deterministico consiste en sólo una constante, y
- el componente aleatorio tiene una variación fija.
El punto clave es que, independientemente de cuántos factores haya, e independientemente de lo complicado que sea la función, y si el analista tiene éxito en la elección del modelo, entonces las diferencias (residuos) entre los datos de respuesta y los valores pronosticados por el modelo deben comportarse como un proceso univariado, el cual tendrá:
- Aleatoriedad, o ruido blanco para series de tiempo
- una distribución dada
- una medida de posición fija dada (cero en este caso)
- una medida de dispersión fija dada
Por otro lado, si los residuos del modelo escogido violan uno o más de los supuestos univariantes anteriores, entonces el modelo escogido es insuficiente y existe una oportunidad de hallar un modelo mejor.
Importancia
La predictibilidad es por lejos el objetivo más importante de un análisis estadístico. Pero para que se cumpla dicho objetivo debemos tener el proceso "bajo control estadístico", condición que se cumple cuando las cuatro condiciones mencionadas se comprueban y tenemos suficientes seguridades de que se seguirán cumpliendo en el futuro.Técnicas gráficas para comprobar los cuatro supuestos básicos
Existe un innumerable conjunto de herramientas numéricas y gráficas para testear los cuatro supuestos. Nosotros nos centraremos en un conjunto reducido de técnicas gráficas, que aprenderemos a desarrollar con lenguaje R. Considero que las mismas cumplirán de manera simple y eficiente el análisis EDA de cualquier serie univariada. Utilizaremos el siguiente set de gráficos que pasaremos a llamar "4-plot":- gráfico de secuencias
- gráfico de rezagos o diagrama de fase
- histograma
- gráfico de probabilidad normal o P-P Plot
Construcción de los gráficos con R
A continuación detallo el código necesario para construir los gráficos. Dejé el código comentado y muy simple para que pueda ser reutilizado facilmente:## 4-Plot ## Generando los gráficos de 4-plot para los datos.
## La variable con datos es y. Es un array univariado. No funciona con data.frame
## El data.frame se puede convertor a array con el comando y <- as.array(y)
##variable de conteo n <- length(y) t <- 1:n ## parámetros de gráfico ## mfrow: nro de gráficos c(nr,nc) 2x2=4, al ser mfrow y no mfcol, se enumeran por fila ## oma: márgenes externos entre gráfico y texto c(bottom, left, top, right) ## mar: márgenes internos entre área de trazado y gráfico c(bottom, left, top, right) par(mfrow = c(2, 2), #2 filas por 2 columnas# oma = c(0, 0, 2, 0), #márgenes externos# mar = c(5.1, 4.1, 2.1, 2.1)) #márgenes internos# ##gráfico de secuencias plot(t,y,ylab="Y",xlab="orden",type="l") abline(h=mean(y), add=TRUE, col="blue") abline(h=-2*sd(y), add=TRUE, col="blue", lty="dashed") abline(h=2*sd(y), add=TRUE, col="blue", lty="dashed") ##gráfico de fases o lags plot(y[-1],y[-n],xlab="Y[i-1]",ylab="Y[i]") ##gráfico de histograma hist(y,main="",xlab="Y",ylab="f(Y)",freq=FALSE) curve(dnorm(x,mean=mean(y),sd=sd(y)), add=TRUE, col="blue") ##gráfico QQPlot normal qqnorm(y,main="",xlab="teórico",ylab="muestra") qqline(y,col="blue") mtext("4-Plot", line = 0.5, outer = TRUE) ##gráfico QQPlot normal
Veamos cómo funciona a través de ejemplos:
Ejemplo 1: números aleatorios distribuidos normalmente
Sería este el caso ideal donde se cumplen los 4 supuestos básicos. Nos servirá para presentar los gráfico en un estado "ideal".
Generamos primero una sucesión de 200 números distribuidos normalmente
y <- rnorm(200,0,1)
Luego ejecutamos el código R provisto en la sección anterior. El resultado debe ser similar a este:
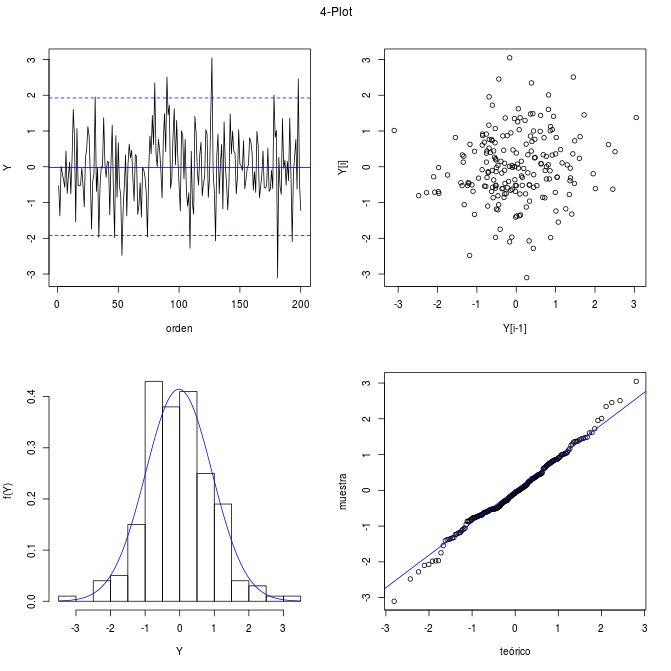
Veamos qué podemos aprender. Primero vayamos investigando cada uno de los 4 supuestos básicos:
- una medida de posición fija: si la hipótesis de cumple, el gráfico de secuencias (esquina superior izquierda) debe ser uniforme y sin tendencia. Puede apreciarse ello en el gráfico.
- una medida de dispersión fija: si la hipótesis de cumple, el gráfico de secuencias debe tener la misma amplitud sobre todo el eje x.
- aleatoriedad o ruido blanco: en caso de no haber un comportamiento correlacionado o determinista entre los datos. El gráfico de lags no debe mostrara patrones identificables, tal como se muestra en segundo gráfico arriba a la derecha.
- una distribución dada: en dicho caso, el histograma (esq inf izq) debe ajustar a la curva supuesta y el P-P Plot (esq inf derecha) mostrarse en línea recta. En este caso (y en el código R) la distribución subyacente es la Normal y se aprecia en los gráficos un buen ajuste a los datos.
Ejemplo 2: reflexiones de un láser
El siguiente ejemplo toma una muestra del año 1969 de 200 disparos de láser, computando su desvío en cada uno de ellos[1] -213 -564 -35 -15 141 115 -420 -360 203 -338 -431 194 -220 -513 154 [16] -125 -559 92 -21 -579 -52 99 -543 -175 162 -457 -346 204 -300 -474 [31] 164 -107 -572 -8 83 -541 -224 180 -420 -374 201 -236 -531 83 27 [46] -564 -112 131 -507 -254 199 -311 -495 143 -46 -579 -90 136 -472 -338 [61] 202 -287 -477 169 -124 -568 17 48 -568 -135 162 -430 -422 172 -74 [76] -577 -13 92 -534 -243 194 -355 -465 156 -81 -578 -64 139 -449 -384 [91] 193 -198 -538 110 -44 -577 -6 66 -552 -164 161 -460 -344 205 -281 [106] -504 134 -28 -576 -118 156 -437 -381 200 -220 -540 83 11 -568 -160 [121] 172 -414 -408 188 -125 -572 -32 139 -492 -321 205 -262 -504 142 -83 [136] -574 0 48 -571 -106 137 -501 -266 190 -391 -406 194 -186 -553 83 [151] -13 -577 -49 103 -515 -280 201 300 -506 131 -45 -578 -80 138 -462 [166] -361 201 -211 -554 32 74 -533 -235 187 -372 -442 182 -147 -566 25 [181] 68 -535 -244 194 -351 -463 174 -125 -570 15 72 -550 -190 172 -424 [196] -385 198 -218 -536 96
En este caso, los gráficos resultaron ser:

Verifiquemos las hipótesis:
- una medida de posición fija: el gráfico de secuencias no presenta tendencias
- una medida de dispersión fija: el gráfico de secuencias presenta aproximadamente la misma variación a través de todo su recorrido.
- aleatoriedad o ruido blanco: El gráfico de lags muestra un patrón muy específico, confirmando que la serie no es aleatoria.
- una distribución dada: siendo que se comprobó que no existe aleatoriedad, los gráficos de histograma y P-P plot no tienen un significado útil.
Daré a continuación un modelo al cual ajustan mejor los datos, sin explicar en detalle cómo se llegó a esta nueva propuesta. Sólo diré que El gráfico de lags sugiere una función sinuidal u oscilante

siendo C una constante de nivel, alfa la amplitud, omega la frecuencia y tita la fase de la función seno.
Analizaremos los errores de medición y - y modelado para ver si el muevo modelo pudo capturar la parte determinista con éxito
t <- 1:length(y) C <- -178.786 AMP <- -361.766 FREC <- 0.302596 PHASE <- 1.46536
e <- C + AMP*sin(2*pi*FREC*t+PHASE) - y
En la última línea hemos restado la parte determinista a los datos reales. Los gráficos de residuales e son:

Verifiquemos nuevamente las hipótesis sobre los residuos o parte aleatoria:
- una medida de posición fija: el gráfico de secuencias no presenta tendencias
- una medida de dispersión fija: el gráfico de secuencias presenta saltos durante su recorrido, indicando que aún es mejorable el modelo en este aspecto.
- aleatoriedad o ruido blanco: El gráfico de lags no muestra patrones.
- una distribución dada: los gráficos de histograma y p-p Plot muestran una distribución aproximadamente normal centrada en cero (insesgado). Quizás haya una leve asimetría hacia la derecha por la caída izquierda del p-p Plot.
- los gráficos muestran la existencia de 4 o 5 valores extraños,
- hay una asimetría muy leve que se puede tratar,
- también hay oscilaciones en la amplitud vistas en el diagrama de secuencias que se podrían capturar volviendo a cambiar la constante C por un modelo más complejo.
Así y todo, los resultados son lo suficientemente satisfactorios para realizar inferencias. Así, adoptamos el nuevo modelo.
Este es el listado de preguntas que se pueden responder con este set de gráficos:
Conclusiones
La herramienta 4-plot desarrollada es muy efectiva para validar los cuatro supuestos subyacentes. Incluso nos aporta más información para resolver los hipótesis no cumplidas y pensar en un nuevo modelo.Este es el listado de preguntas que se pueden responder con este set de gráficos:
- Está el proceso en control; es estable y predecible?
- El proceso muestra tendencias en su posición?
- El proceso muestra tendencias en su variación?
- Los datos son aleatorios?
- Las observaciones están relacionadas con las observaciones adyacentes?
- Si los datos son una serie de tiempo, se trata de un ruido blanco?
- Si los datos son una serie de tiempo y no se trata de un ruido blanco, es un modelo autoregresivo o sinusoidal?
- Los datos o residuos siguen una distribución normal?
- Si no es normal, qué forma tiene la distribución?
- Es el modelo Y = C + e válido y suficiente?
- Si el modelo básico es insuficiente, hay posibilidad de mejorarlo?
- Es la varianza muestra un buen estimador de variación?
- Es la media muestral un buen estimador de posición?
- Si no lo fuera, cuál sería mejor?
- Existen valores extraños (outliers)?
No hay comentarios:
Publicar un comentario